Mastering Aggregates in Domain-Driven Design
Key concepts and implementation


So far we have discussed the basic building blocks of Domain-Driven Design:
entities - objects that have a distinct identity that doesn't change throughout the life of an object, even though their other attributes might change,
value objects - objects without a specific identity, that are identified by their attributes or properties.
However, we often need more complex domain concepts, namely the composition of entities and value objects acting as a whole. Such a concept is called an Aggregate and this is an essential pattern in Domain-Driven Design.
The structure of an aggregate
From a structural point of view, an aggregate is a graph of entities that conceptually belong together:
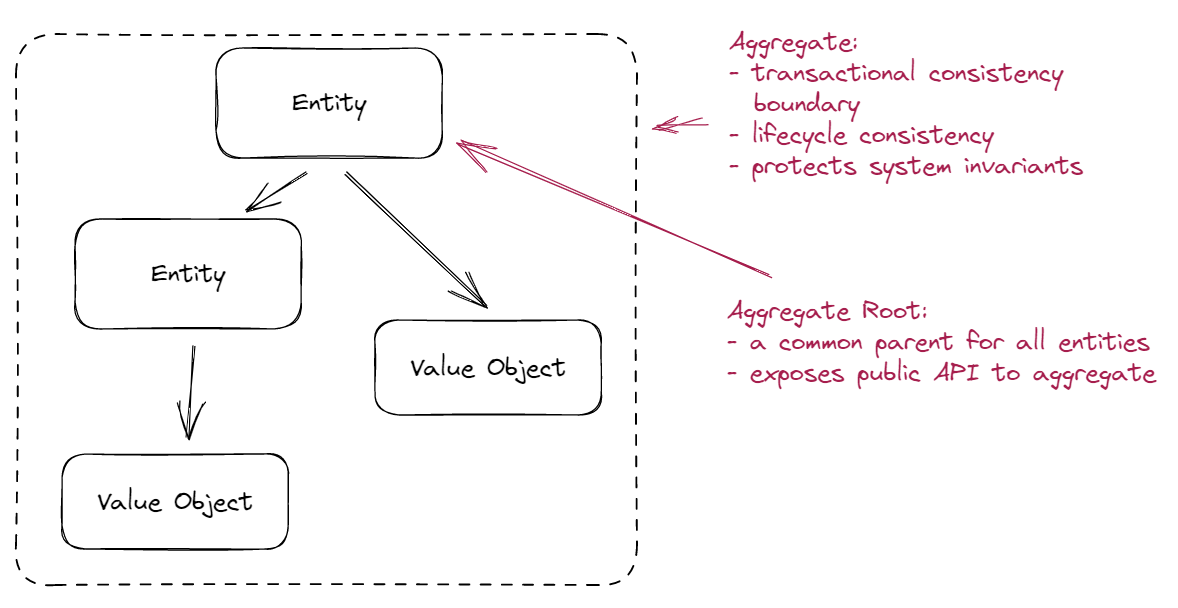
The top-most entity is an aggregate root - as the name implies, this is a root node in the hierarchy, which exposes the top-level API of the Aggregate and controls the lifecycle of all its child nodes. This means that the outside world can communicate with the aggregate only via the root, and cannot directly manipulate its children.
From a logical point of view, an aggregate is all about behavior - Domain-Driven Design advocates for a Rich Domain Model, where business logic, rules and constraints are encapsulated within the entity itself. The common approach here is to have an aggregate root with clearly defined interface, that implements all rich behaviors of the aggregate. Thus, if the outside world wants to change the state of the aggregate, it should call a specific method of the aggregate root. Such method should not only guard against access to aggregate internal data, but also should check any business or invariants that the aggregate must follow.
This is in contrast to anemic domain model (a model that includes only data and no behavior), which is an anti-pattern. If your entities are only about data and all the logic is located in separate classes or functions, you are doing it wrong.
Let’s look at an example. In a online auctions system, we can define a Listing Aggregate. A listing represents an item for sale, which is created by a seller (another aggregate). When bidding starts, buyers can place bids, by providing a maximum amount they are willing to pay for an item. When bidding ends, the buyer with the highest bid wins.
Let's look at an example of an aggregate in our system - a Listing:
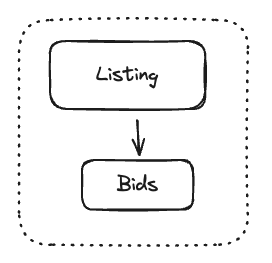
It consists of a Listing aggregate root, and a collection of Bids. The root will contain such information as identity (id) of a seller (yet another aggregate), initial price, listing end date, etc. Bid is a value object that could contain an offered amount, identity of a bidder, etc.
Logical Boundary
The key idea behind aggregate is maintaining business invariants and preserving data consistency. Simply speaking, invariants are rules or constraints that must always hold true - they define the core business logic and rules of the domain being modeled.
Let's look again at our example. There are multiple rules that bidding process must follow. First of all, each listing has an minimum price (asking price) that is being set by a seller. Therefore, a bid must be greater than the ask price. Also, a bid must be greater than the current price of a item, which results from other bids already placed on an item. Moreover, bids cannot be placed on listing, which already ended, etc.. There may separate rules for canceling listings (by sellers), or retracting own bids (by bidders). We can express some of these rules as the invariants:
Minimum Bid Requirement: The current bid must always be higher than or equal to the initial price set by the seller, and any subsequent bids must be higher than the current highest bid.
Bid Increment Rules: Each new bid must exceed the previous bid by at least a set minimum increment. This increment can be a fixed amount or a percentage of the current bid.
Listing Duration: A listing has a fixed duration. No bids can be accepted before the listing starts or after it ends. This ensures that the auction operates within the defined time frame.
The key role of an aggregate is to enforce these invariants for all objects under control of the aggregate. This can be achieved by exposing a public interface of an aggregate via the aggregate root:
class Bid(ValueObject):
bidder_id: BidderId
amount: Money
class Listing(AggregateRoot):
bids: list[Bid]
def place_bid(self, new_bid: Bid):
"""places new bid on a listing"""
# 1. check invariants/rules for placing a bid
# 2. add `bid` to `self.bids`
…
def retract_bid_of(bidder: BidderId):
"""retracts a bid already placed by a bidder"""
# 1. check invariants/rules for retracting a bid
# 2. find bid placed by `bidder` and remove it from `self.bids`
...
Given the interface, the only possibility of adding a new bid to a listing is by calling place_bid method. If we allow manipulating bids directly (i.e. via the database), then there is serious risk of breaking the constraints, and we should avoid it at all cost.
Transactional Boundary
We already learned that Aggregates are designed to enforce invariants, which are rules ensuring the consistency and correctness of the data within the aggregate. A transactional boundary guarantees that all changes to the data within the aggregate are either fully completed or fully rolled back, and the integrity of these invariants is preserved. Therefore any change to an aggregate state must occur within a single transaction. In addition, in a system where multiple users or processes can modify data concurrently, transactional boundaries help manage concurrency, but this is beyond the scope of this post.
Finding the right boundary
Now you may ask: “How big should be my aggregate”? Let’s look at the extremes of the spectrum to better understand the potential pitfalls.
The bigger the aggregate, the easier it is to enforce the invariants. On the extreme, the entire system could be one huge aggregate. However, as aggregate get bigger, the harder it is to fit it into a memory, I/O operations will take more time, and concurrent access to the aggregate becomes more complicated. On the other side of the spectrum, small aggregates support concurrency better, but it’s harder to fulfill the invariants or constraints.
Again, let’s look at the example. Let’s say we want to satisfy the Bidder Eligibility invariant: only registered and approved bidders can place bids (this might include checking the bidder’s account status or other eligibility criteria). Currently our Listing aggregate does not contain bidders at all, so we cannot satisfy this constraint in the aggregate itself. What options do we have then?
Enlarge the aggregate, so that now it contains all the bidders. It’s possible in theory, but imagine the consequences, the memory footprint will be huge, and placing bids concurrently would result in a write conflict.
Replace invariant with a corrective policy: we can talk to the business (yes!) and loosen the constraint. Maybe it would be acceptable that ineligible bidder places a bid, and after some time we will take a corrective action to remove the bid and notify both bidder and seller.
Provide the aggregate with external means of verifying the constraint. We could add another parameter to place_bid method:
def place_bid(self, new_bid: Bid, check_bidder_eligibility: BidderEligibilityService):
check_bidder_eligibility(new_bid.bidder)
# do the rest of checks
…
Solution #3 seems to be the easiest. However, keep in mind that this solution is not bulletproof. A race condition still may occur, that will lead to aggregate violating the constraint (but this is a topic for another article). That’s why backing it up with #2 is in my opinion the best idea.
In reality, finding the right boundary is the most challenging part of the aggregate design.
Other considerations
Here are some other random thoughts on aggregates.
Aggregates are Optimized for Writes
In any system, interactions occur either through querying the current state (reading) or modifying the state (writing). Aggregates are specifically optimized for writing operations, given their complexity and logic-rich nature. For reading, a simpler approach like using Data Access Objects (DAOs) may suffice. This avoids the unnecessary overhead of converting database structures into domain objects just for displaying data.
Aggregate Persistence
The persistence of aggregates should always be managed through repositories. There should be a one-to-one relationship between an aggregate and its corresponding repository. Repositories serve to abstract the details of the underlying data storage, offering a collection-like interface for managing aggregates. On the infrastructure level, it's crucial to ensure that any modification to an aggregate is performed within a transaction. This guarantees the consistency and atomicity of all changes.
Handling Aggregate Relationships
Aggregates should reference each other by identity rather than direct object references. This approach preserves the independence of each aggregate and prevents the persistence of one from unintentionally impacting another. This concept might seem counterintuitive initially, especially if you are accustomed to Object-Relational Mapping (ORM) systems. However, it's a fundamental principle for maintaining the integrity and autonomy of aggregates in a domain-driven design.
Key takeaways
Aggregates as Composite Units: Aggregates combine entities and value objects, enforcing business rules and data consistency.
Central Role of Aggregate Roots: Aggregate roots manage the integrity of the aggregate, acting as the primary interaction point.
Upholding Business Invariants: Aggregates ensure consistent application of business rules and constraints.
Balancing Aggregate Size: The design of aggregates involves a balance between size and complexity, affecting performance and invariant enforcement.
Transactional Integrity: Aggregates are optimized for write operations, maintaining transactional consistency and integrity.